
le protocole HTTP
Pour la source, découvrir par vous-même quel est le protocole général. Protocole - est un ensemble de règles et de personnages clés, destinés à la communication entre un dispositif. Il est nécessaire pour que les ordinateurs ou leurs éléments peut bien comprendre le copain de copain.
Minutes - parlant des ordinateurs de communication sur le réseau.
En fait, juste un ensemble de commandes a permis de nommer le protocole, mais en pratique le concept de protocole applique uniquement aux dits protocoles réseau - ordinateurs de communication de langue sur le réseau. Chaque protocole a un but précis et soutenu par un logiciel spécialisé.
URL, les adresses IP et DNS, les domaines
Donc URL (Uniform Resource Locator) est le chemin complet du document. URL est l'adresse à ce qui a permis de trouver définitivement le document (fichier) sur Internet. Cette ligne que vous tapez dans la boîte "e" navigateur vyshego aussi manger l'URL du document.
URL peut posséder assez une sorte de délicate, comme sotoyat de diverses parties. Considérons d'abord une URL simple:
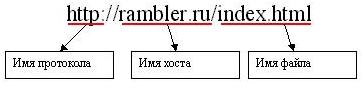
Cette URL comporte trois éléments constitutifs: le nom d'hôte où le document, le nom du protocole sont utilisés pour transmettre le document, le nom réel de l'acte (le nom du fichier ainsi que l'extension). La base (et la seule action obligatoire pour le protocole HTTP) Adresse - un nom d'hôte. Il identifie la machine sur laquelle l'acte (dans les ordinateurs individuels réseau de nom d' hôte). Chaque ordinateur sur le réseau est l'hôte dispose également d'un (au réseau) nom unique. Dans l'échantillon Rambler.ru le nom de l' ordinateur sur lequel nous voulons trouver un document.
Les noms d'hôte peuvent être définies moyens redondants: en utilisant le DNS et l'utilisation des adresses IP. Une adresse IP se compose de quatre nombres séparés par des périodes. Chaque montant peut être dans la plage de 0 à 255. Par exemple 192.168.2.1.
En pratique, cependant peu pratique à utiliser l'adresse IP que le nombre de difficile à retenir. Ainsi était vvedna Domain Name System (Domain Name System - DNS), dans lequel chaque adresse IP est placé dans une relation ou un nom composé de lettres ou de chiffres. Par exemple , dans le nom de l' échantillon DNS ci - dessus était rambler.ru, car elle correspond à l'adresse IP 217.73.192.109.
Il convient de noter que les adresses IP différentes prkticheski correspondent toujours à des noms DNS différents, mais les noms DNS différents peuvent répondre à la même adresse IP. Par exemple, comme un des noms de DNS, et www.rambler.ru rambler.ru ont un puits que bla bla adresse IP. Les adresses URL sont autorisés à utiliser les noms DNS et adresses IP. Ainsi, les deux adresses URL en tant http://rambler.ru/index.html http://217.73.192.109/index.html équivalent. Certaines méthodes d'affectation d'adresses IP sont décrites ici http://www.xakep.ru/post/11980/default.htm .
Nous notons également que, en principe, l'hôte n'a pas à posséder le nom de domaine. Autrement dit, certains hôtes sont autorisés uniquement accès par adresse IP.
Vous avez probablement déjà remarqué le soin que tout nom DNS se compose de plusieurs mots séparés par des points. Chaque domaine de nom seul signifie que l'hôte. Le système DNS entier est construit de manière hiérarchique. Tous les domaines de niveau 1 (com, org, fr, etc.) inclus dans le domaine racine de niveau 0 (qui est généralement pas écrit parce que le DNS est la valeur par défaut). un autre niveau domaines (tels que rambler, courrier ou kiev) viennent en domaines du niveau principal et etc. Les domaines dans les DNS sont écrites de droite à gauche, dans l'augmentation quotidienne du niveau.
Remarque deux caractéristiques importantes: 1. Le domaine est purement une unité administrative est également pas un hôte. 2. Les numéros IP ne dépend pas du domaine dans lequel l'hôte.
Ainsi, le système de domaine a été introduit juste pour le classement des sites par l'attribut géographique ou de la cible, et ne posséder aucune relation avec le dispositif physique à Internet.
Dans privdennom l'échantillon URL que nous avons demandé explicitement le nom de la loi , nous sommes intéressés par le index.html, mais il y a un document sur chaque site pour être ouvert par défaut. Il occupe le poste comme le nom index.html ou default.html également situé dans le dossier racine du site. Si nous entrons dans l'adresse URL du site ne précise pas comment nous voulons avec le nom du fichier, le serveur ouvrira automatiquement pour nous un acte adopté par défaut. Ainsi traitent http://crackchat.h1.ru équivalent à http://crackchat.h1.ru/index.html. Tout comme il y a un fichier bla bla ouvre par défaut, il y a aussi le dossier Boîte de réception par défaut. Dans la plupart des serveurs, le dossier par défaut pour les documents HTTP a le nom WWW.
Après le DNS dans l'URL doit être le nom de la loi à laquelle nous nous référons. Cela suppose que le fichier est dans le dossier racine. Si blah blah il ne fait pas, alors nous pouvons spécifier le chemin complet du certificat, la liste des sous-dossiers par la barre oblique:
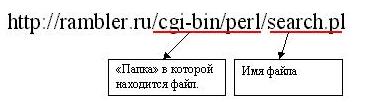
Dans cet exemple, nous nous référons à un fichier dans le cgi-bin / perl / répertoire. Ce chemin est relatif au dossier racine. Par exemple, si le chemin à la racine de f: / www, puis dans notre exemple, nous nous tournons vers le fichier f: /www/cgi-bin/perl/search.pl. Dans le même temps fièrement noter ce qui suit: que la plupart du serveur Web est construit sur les systèmes de type UNIX, puis lorsque vous spécifiez le chemin vers le fichier que vous devez prendre en compte la différence entre les lettres minuscules et majuscules. Donc , si nous nous référons au dossier par URL http://rambler.ru/CGI-BIN/perl/Search.pl, le serveur aurait un tel fichier non trouvé. La différence est aussi impressionnant de petites lettres vient seule voie vers un fichier, DNS est est insensible à la casse (qui mangent adresse rambler.ru comme RAMBLER.RU équivalent).
Comme mentionné, le DNS est conforme adresse IP strictement opredelnie, mais cela ne signifie pas que le nom DNS est équivalent à l'hôte auquel nous nous référons. Souvent, l'hôte lui seul détient en lui-même un sans fond les niveaux de domaines. Par exemple le site h1.ru est un hôte dans un domaine autre niveau, mais il contient les domaines de troisième niveau, comme crackchat.h1.ru ou crosswords.h1.ru. Par conséquent, la paire appartiennent à un site d'accueil unique et sont naturellement la même adresse IP! Physiquement, dans ce cas, les domaines de troisième niveau ressemblent à des dossiers sur le disque h1.ru hôte également accessible pourrait être mis en œuvre , tels que: h1.ru/crackchat/ h1.ru/crosswords/~~V~~singular~~3rd aussi. moyens d'accès (à travers le domaine de 3e niveau ou par l'intermédiaire d'un chemin de disque) est déterminée par les paramètres du serveur.
Domaine racine est considéré comme similaire, et donc la majorité des adresses URL sont autorisés à indiquer dans une paire de formats: à la fois le nom de domaine www (par exemple www.crackchat.h1.ru), ainsi que sans elle (crackchat.h1.ru) - dans ce cas, le serveur sera toujours vous dirige automatiquement vers le dossier www parce qu'il est adopté par défaut.
Protocoles, ports, protocole CGI
Comme nous l'avons vu, l'adresse URL se compose de trois éléments de base: nom DNS, chemin du fichier, ainsi que le nom du protocole. Si le premier élément de la paire peut déterminer l'emplacement du document, le protocole définit les modalités d' accès au document. En d' autres termes, à quel moment le client tente d'obtenir le document, il est forcé de dire au serveur comment il (le serveur) est forcé à l'acte , il (le client) pour transférer. Il existe de nombreux protocoles différents de transmission de données dans le réseau, y compris le http plus commun (Hypertext Transfer Protocol - Hypertext Transfer Protocol), ftp (File Transfer Protocol - File Transfer Protocol), mailto (préfixe protocole de messagerie suite), (protocoles d'accès aux fichiers de fichiers ou dossiers). le type de protocole définit le programme qui traitera les données dans le format de protocole. Parce que Internet Explorer peut fonctionner avec les protocoles http, fichier et ftp, mais il ne peut pas fonctionner avec le protocole mailto. Par conséquent, si vous tapez dans votre navigateur, dans la barre d'adresse mailto: microsoft.com, puis exécutez un programme e-mail spécialement conçu qui peut fonctionner avec le protocole (par exemple Outlook Express ou The Bat!). Le nom du protocole indique le plus important dans l'URL doit également être suivi par un colon. Enregistrer la valeur n'a pas d'importance.
Parmi les protocoles trouvés assez bizarre, comme protocole de résolution ou au sujet (pour les intérêts peuvent taper dans la barre d'adresse du navigateur cette adresse sur: <a href="mailto:[email protected]"> envoyer le projet de loi de voeux </a> également voir quelle sera la  . Un autre protocole ldap divertissant (essayez par exemple ldap: //microsoft.com).
. Un autre protocole ldap divertissant (essayez par exemple ldap: //microsoft.com).
En tant que protocole pour l'URL ne peut pas agir tous les protocoles. Donc , des rapports sur ou javascript n'a pas aucune relation avec le remplissage de la route le document, aussi parce que «l'adresse» avec ces protocoles ne sont en aucun URL.
préfixe de protocole indique au client sur ce «langage» coulera communication avec le serveur. Et le client sait à l'avance ce que le programme devrait garder cette communication, qui ne peut être dit sur le serveur. Afin d'être le serveur a commencé à «parler» avec nous sur le langage de protocole requis, il (le serveur) doit exécuter un programme approprié qui comprendra ce protocole. Pour résoudre ce problème, utilisez les ports. Donc , si le nom ou l' adresse IP DNS de la machine est déterminée à laquelle nous nous référons, le port détermine le programme auquel nous nous tournons sur un hôte donné. Les ports désignés nombre entier allant de 0 à 65535.
Chaque protocole est assigné le port par défaut sur lequel le programme serveur va attendre les demandes des clients. Par exemple, si le serveur prend en charge le protocole HTTP, le logiciel serveur correspondant (par exemple Apache) attendra les demandes des clients sur le port 80 (le port par défaut du protocole http reçu). Si ce bla bla hôte prend en charge plus de protocole ftp, puis l'autre programme serveur écoute sur le port 21 (le port est réservé pour le protocole FTP).
Port auquel nous nous référons est déterminé automatiquement, en fonction de ce protocole, nous avons choisi dans l'URL. Mais le port a également permis de préciser explicitement. Le numéro de port est spécifié dans le côlon après le nom DNS ou l'adresse IP:
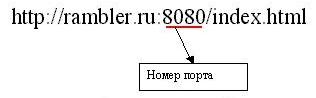
Dans cet exemple, nous nous tournons vers un certain programme, "suspendu" sur le port 8080, prétend également qu'elle a à nous donner le fichier index.html via le protocole http. Si srevere un tel programme ne semble pas (puis manger les requêtes vers le port 8080 aucun programme en aucune façon ne sera pas suivi), le navigateur va nous donner un message sur la mauvaise URL.
Parce que le port du serveur http par défaut 80 est adopté, le http://rambler.ru:80 équivalent d'adresse à http://rambler.ru. Bien qu'en principe, les hôtes ne sont pas tenus de le maintenir dans le port http 80 e. Le serveur peut être configuré par exemple pour le port 3128, également au moment de communiquer avec l'hôte à http nécessité incessante de spécifier explicitement le numéro de port: http://rambler.ru:3128
Lorsque l'accès au serveur parfois, il arrive, il est nécessaire de préciser, en plus d'agir à la même adresse idntifikator utilisateur qui accède au serveur (ou à laquelle nous nous tournons sur le serveur), mais similaire à un mot de passe. URL vous permet de transmettre ces informations. Pour ce faire, avant le nom DNS est placé avant le signe @ qui indique le nom d'utilisateur:
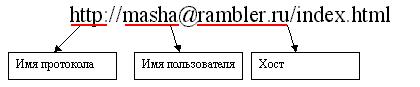
En règle générale, pour le protocole http ne nécessite pas d' authentification de l' utilisateur, mais pour des protocoles tels que FTP ou mailto dont elle avait besoin. En plus du nom d'utilisateur, indiquez le mot autorisé et l'accès. Mot de passe est plus au nom du côlon. Par exemple: ftp: // masha: [email protected]. Cette demande d'adresse URL via ftp répertoire racine du yahoo.com hôte de la kacha utilisateur mot de passe masha. Mais cette adresse mailto: //[email protected] utilisé pour accéder à la boîte aux lettres de l'utilisateur dans le mail.ru. masha hôte
Nom polzovaetlya similaires peuvent exister sont structurés sur le principe de domaine, également composé de différents éléments, séparés par un point. Par exemple mailto: //[email protected].
Comme mentionné, l'URL est le chemin complet du document. En vertu de la loi signifie tout fichier, qui peut exister sous forme de texte (par exemple, html ou fichiers pdf ou doc) et de l'image (jpg ou gif), et le programme. Cela signifie que le protocole http si demandé dans le texte de l' URL, ou une image, alors ils doivent être transmis à l'utilisateur afin de les afficher dans leur navigateur, mais si le programme ou le script demandé, alors il doit être exécuté sur le serveur, et l' envoyer à l'utilisateur le résultat de ses travaux. Lui-même le résultat peut être soit du texte ou de l'image. Tapez rezultirueschego acte défini dans le programme lui-même, et l'utilisateur ne sait pas à l'avance quel type de document qu'il reçoit, ce qui provoque le programme. Appelez le programme de serveur via l'adresse URL normale du programme ou d'un script. En règle générale, dans un réseau à l' aide de scripts avec l'extension .pl .cgi .php (les deux premiers représentent des programmes écrits en Perl et PHP, cependant, la dernière prolongation peuvent être appliquées pour tous les exécutables, y compris aussi pour Perl et PHP aussi EXE). Par exemple l' adresse URL de http://www.rambler.ru/cgi-bin/top.cgi est nécessaire pour exécuter sur le rambler.ru hôte certaine application top.cgi également transférer au client le résultat du travail de cette application (par exemple html document ou une image).
Mais à partir des applications serveur ont été un peu confus si elles doivent passer des paramètres était impossible. URL permet. Pour passer des paramètres aux applications basées sur le serveur (également appelés passerelles) en utilisant un format de données connu comme CGI (Common Gateway Interface). Ce format permet au programme de définir les données d'entrée en une seule rangée.

Dans cet exemple montre qu'une URL est appelé un serveur de passerelle transmet également search.pl en entrée un paramètre utilisateur appelé également masha zanacheniem. chaîne de CGI disparaît du problème nom script signe? . Si le script est nécessaire de passer plusieurs paramètres, ils sont listés séquentiellement par une esperluette & caractère, par exemple: http://rambler.ru/cgi-bin/perl/search.pl?user=masha&password=kasha.
Notez ce qui suit: que la plupart des technologies Web basées sur les formats de données texte, le brillant et le début ou plus tard, il y a un problème de distinction entre le code et les données. Par exemple, si en tant que paramètre de CGI, nous voulons transmettre une expression de paramètre avec une valeur de C = A + B: http://site.com/script.cgi?expression=C=A+B une telle demande sera mal compris comme un autre CGI = signe sera perçu comme un séparateur entre le nom du paramètre et sa valeur. Par conséquent, le protocole CGI (ainsi que dans toutes les URL à l' intérieur) utilise un codage de caractères spécial appelé Format de données URL.
Ce codage affiche des lettres de l'alphabet comme ils sont, et le reste des caractères sous la forme% nn où nn - code de caractère hexadécimal. Par exemple , le double caractère de citation "ressemblera à 22%, mais comme un symbole =% exception 3D est le caractère d'espace, qui en plus de la norme de codage de
le protocole HTTP
HTTP (Hypertext Transfer Protocol) - le protocole principal utilisé sur le Web. Bien que le protocole appelle le protocole de transfert hypertexte (par exemple, HTML), la session sur le protocole HTTP peut être utilisé (et est utilisé) pour transmettre des données de pratiquement tous les réseaux. Il transfère également le texte et les images sous forme de fichiers. popularité HTTP, à mon avis, est liée à plusieurs facteurs: il est suffisamment polyvalent pour utiliser l'adressage URL, la capacité de transférer des données (telles que le serveur du client, ainsi que vice-versa), mais un travail similaire dans le mode sans ligne (c.-à-predachi données directement entre client et le serveur, sans intermédiaires). le protocole HTTP appelé double autorisé dans le sens que le système client-serveur, les données peuvent se déplacer dans les directions de la paire, également à partir du client vers le serveur intérieur vers l'extérieur et depuis le serveur vers le client. Pourtant, personnellement syntaxe HTTP est destinée à un transfert de données du client vers le serveur.
Alors regardez juste un échantillon de la requête HTTP. Si la fenêtre d'adresse du navigateur , nous tapons l'adresse http://yandex.ru, le navigateur permettra d' identifier l'adresse IP du serveur enverra également yandex.ru son port 80 une requête HTTP:
GET http://yandex.ru/ HTTP / 1.0
Accepter: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-powerpoint, * / *
Accept-Language: ru
Cookie: yandexuid = 2464977781018373381
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.5, Windows 98)
Hôte: yandex.ru
Referer: narod.ru
Proxy-Connection: Keep-Alive
La demande est envoyée sous forme de texte clair. La première requête est la part dans la première ligne: Ceci est le type de requête (GET), l' adresse URL du document demandé (http://yandex.ru) comme une sorte de protocole HTTP (HTTP / 1.0). D'autres listes les paramètres de la demande. Chaque ligne correspond à un paramètre. A la source de la ligne se déplace le nom du paramètre suivi d'une valeur de deux points et paramètre. Le sens de la mémoire de paramètres est intuitive, mais nous décrire les principales: Accepter - le type de données qui peut prendre le navigateur (MIME codé). Accept-Language - la langue préférée du navigateur veut recevoir les données. User-Agent - un type de programme qui a envoyé la demande. Hôte - DNS (ou IP) Nom de l' hôte auquel la demande est adressée. Cookie - biscuits (données qui étaient stockées sur le serveur, l' unité locale du client, vous visitez l'hôte dernière fois). Referer - hôte avec des pages kotorgo nous nous référons à la demande. Ainsi , par exemple , si nous sommes à la page de http://narod.ru et cliquez il http://yandex.ru lien, la demande sera envoyée au yandex.ru hôte, mais le champ de demande de referer aura le nom du narod.ru hôte.
Un ensemble de paramètres de la requête n'a pas été fixée. En plus de ce qui précède, peuvent également être présents d'autres options.
La mémoire de paramètres les plus intéressants tels que le referer et cookie. Ces paramètres sont principalement utilisés pour le serveur d'authentification de l'utilisateur.
demande GET peut avoir les données transmises par le serveur du client. ils sont transmis directement à travers l'URL pour le protocole CGI. Par exemple, pour accéder au serveur de chat, votre navigateur peut envoyer une demande ultérieure:
GET http://chat.ru/? Login = Algol & passer = Algol HTTP / 1.0
Accepter: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-powerpoint, * / *
Accept-Language: ru
Cookie: yandexuid = 2464977781018373381
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.5, Windows 98)
Hôte: yandex.ru
Referer: narod.ru
Proxy-Connection: Keep-Alive
Kaka, nous voyons la chaîne de requête contient login et mot de passe de l'utilisateur, les messages envoyés à travers la chaîne d'URL. Un tel type de serveur de transmission de données est commode, mais a des limitations sur la capacité. Extrêmement des quantités impressionnantes de données ne peuvent pas transmettre à travers l'URL. À cette fin, il y a un autre type de zprosov: requête POST. Requête POST très similaire à l'EEG, avec la seule différence que seule requête POST de données sont transmises séparément de la tête de la demande réelle. Comme l'échantillon dans un formulaire POST a le formulaire ci - dessus:
POST http://chat.ru/ HTTP / 1.0
Accepter: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-powerpoint, * / *
Accept-Language: ru
Cookie: yandexuid = 2464977781018373381
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.5, Windows 98)
Hôte: yandex.ru
Referer: narod.ru
Proxy-Connection: Keep-Alive
login = Algol & pass = Algol
Comme nous observons les données sur le login et le mot de passe sont transmis séparément dans le corps de la demande. Demande corps doit se détacher de l'en-tête chaîne vide. Si le serveur rencontre une ligne vide dans une requête POST, tous les autres mouvements qu'il considère le corps de la requête (données transmises). Notez les points suivants: danyh format dans le corps de la requête POST est arbitraire. En dépit du fait que le format le plus couramment utilisé CGI, il n'a pas été nécessaire. Outre POST demande ne nécessite pas un corps de requête peut également transmettre des données via URL similaire.
En plus du format CGI, parfois pour transmettre une quantité impressionnante d'informations (comme des fichiers) utilisé la soi-disant Format multipart:
POST http://photo.bigmir.net/form.php HTTP / 1.0
Accepter: image / gif, image / x-xbitmap, image / jpeg, image / pjpeg, application / vnd.ms-excel, application / msword, application / vnd.ms-powerpoint, * / *
Referer: http://photo.bigmir.net/form.php
Accept-Language: ru
Content-Type: multipart / form- données; boundary = --------------------------- 7d20345dc
Accept-Encoding: gzip, dégonflez
User-Agent: Mozilla / 4.0 ( compatible; MSIE 5.01, Windows 98)
Hôte: photo.bigmir.net
Proxy-Connection: Keep-Alive
Pragma: no-cache
Cookie: Ukrainien = 2;
BSX_TestCookie = Oui;
rich_ad = 1;
b = 1
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "id"
254353
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "d"
22
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "login"
Algol
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "passw"
Algol
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "email"
[email protected]
----------------------------- 7d20345dc
Content-Disposition: form-data;
name = "submit"
ajouter
----------------------------- 7d20345dc--
Laissez - nous préoccupation sur la barre de titre de Content-Type: multipart / form- données; boundary = --------------------------- 7d20345dc. Ce paramètre exprime le serveur que le client envoie les données dans le c limiteur format multipart --------------------------- de 7d20345dc. Le limiteur est généré aléatoirement par le client est également nécessaire de veiller à ce que serevere être capable de séparer les différents éléments envoyés dans le corps de la demande. Comme vous pouvez le voir, le corps contient un certain nombre d'éléments qui sont transmis en format ASCII (mais pas en Unicode comme nécessaire pour CGI) a également partagé qu'une chaîne qui a été spécifié dans la mémoire de paramètre Content-Type. Chaque lobe contient des informations sur le type de données transmises et le nom de cette partie. Confort Format multipart est que les données transmises ont une valeur illimitée aussi ne nécessite pas de pré-encodage.
Outre les requêtes GET et POST, il y a aussi d' autres, comme TRACE, PUT. Mais ils sont rarement utilisés, et nous ne nous attarderons sur eux.
Un autre jour, je vais tourner la prise en charge du fait que toutes les informations transmises au serveur de client est contenue dans le titre et le corps de la demande. Une autre façon, le serveur ne peut pas obtenir de l'information du client sur HTTP.
D'autre part, et le serveur peut transférer au client iformatsii seule objection à la demande. Toute danymi d'échange dans le protocole HTTP est initié uniquement par le client, le serveur ne peut pas passer quoi que ce soit "juste parce que" , mais seulement sur demande.
Ainsi, si nous possédons la capacité de contrôler si la demande transmise, nous avons pleinement kontrolliruem reçu par les informations de serveur et le client. Ceci est utile pour la modification des données transmises / demandée n'a pas besoin de modifier les fichiers de pages HTML, izmenenyat, biscuits et ainsi de suite, mais assez pour faire des changements dans la requête HTTP et l'envoyer au serveur. Mais cela est une autre chronique ...



Commentaires
Commentant, gardez à l' esprit que le contenu et le ton de vos messages peuvent blesser les sentiments des gens réels, montrer du respect et de la tolérance à ses interlocuteurs, même si vous ne partagez pas leur avis, votre comportement en termes de liberté d'expression et de l' anonymat offert par Internet, est en train de changer non seulement virtuel, mais dans le monde réel. Tous les commentaires sont cachés à l'index, le contrôle anti - spam.